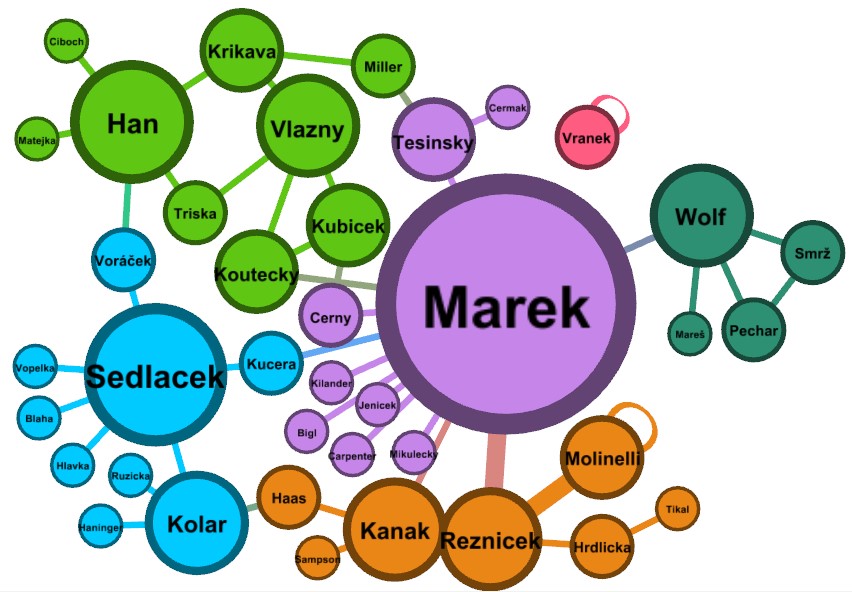
|
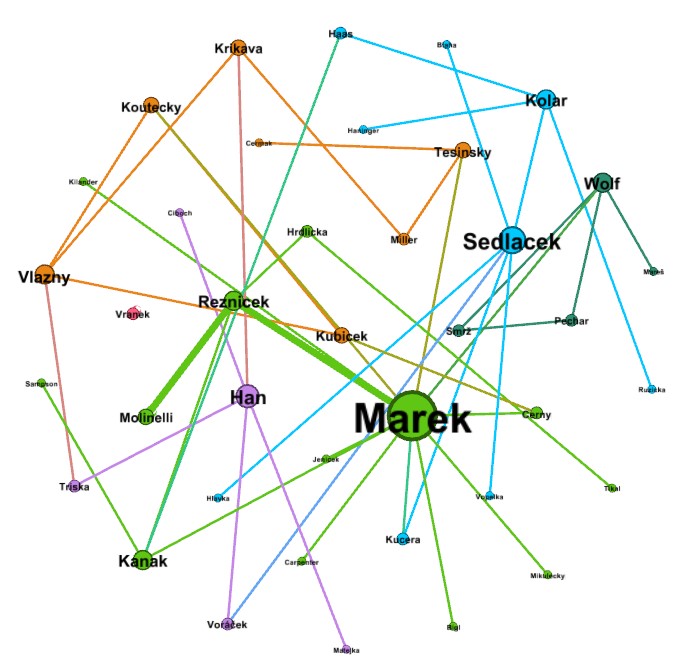
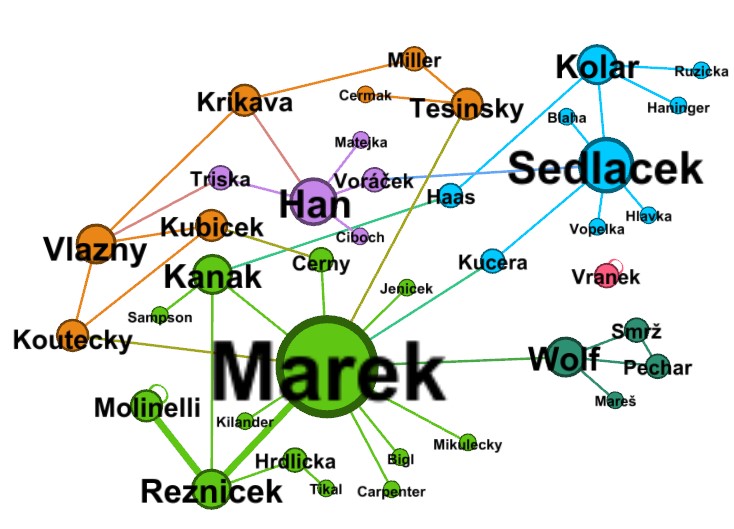
The Input File
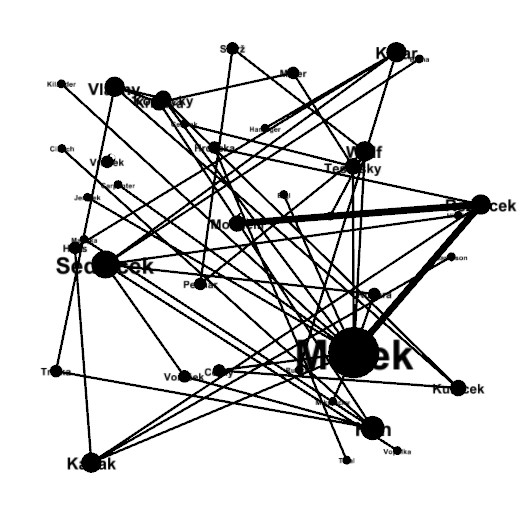
The input file is simply a list of the pair of surnames for every marriage. However, this takes a good deal of data preparation to make the result best. The data preparation has these steps:
- I download the master marriage list from my database on Legacy Family Tree into an Excel spreadsheet.
- I first use Excel formulas to create columns of only the surnames of the husband and wife.
- I then "clean up" the data by removing the marriages for which one or both surnames are not known.
- I also standardize the spelling of the surnames so that the same families show in the same node of the graph and also so that I eliminate any diacritical marks of the Czech surnames.
- I then duplicate the list with the names of the husband and wife switched so that both lists have all the surnames.
- I then save the file with the first worksheet being my input to GEPHI.
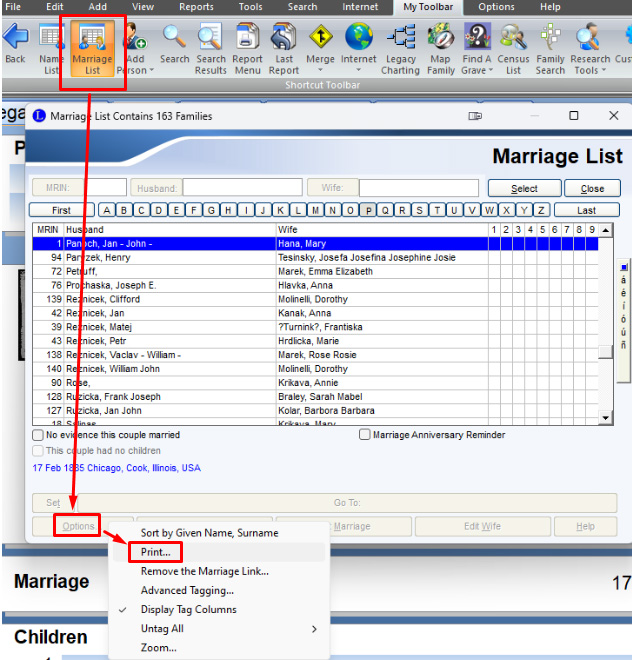
The Input File - Step 1: Download Master Marriage List
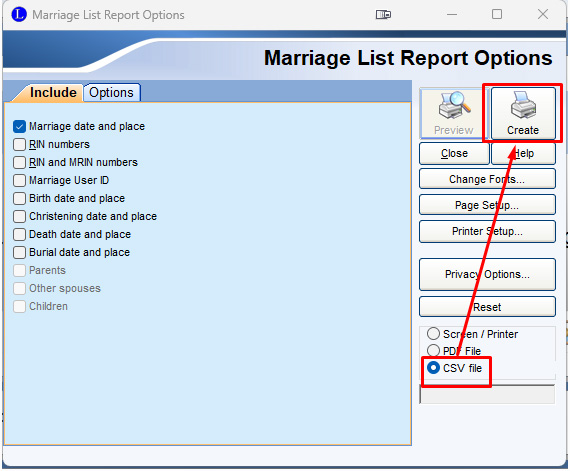
Presumably, other genealogical database software programs allow viewing and downloading a list of all the marriages in the database. I used Legacy Family Tree to do it. (If you don't have Legacy and want to use it for this, you can download it free at https://legacyfamilytree.com/DownloadLegacy.asp and import your GEDCOM into it.) Click on "Marriage List". Then click "Options" and "Print ...". In the new window that pops up, click the check circle for "CSV file" and then "Create" to save the marriage list to a CSV file with whatever name you want in whatever folder you want.
The Input File - Step 2: Create columns with just the surnames
Open the downloaded file in Excel. It will look like this.
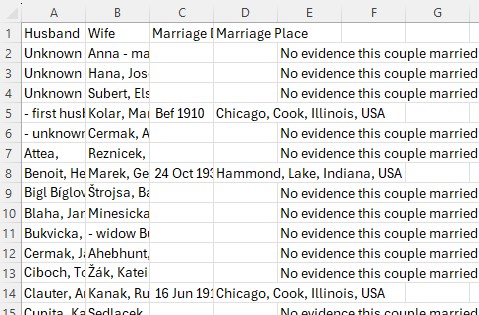
In two adjacent blank columns to the right (I title them "Hsur" and "Wsur" for Husband and Wife surnames), in the second row, enter this formula for the Hsur column:
=LEFT(A2,FIND(",",A2)-1) -- which finds the location from the left of the first comma in the husband's name field and then sets the surname to the text to the left of the comma
And enter this formula for the Wsur column:
=LEFT(B2,FIND(",",B2)-1) -- which finds the location from the left of the first comma in the wife's name field and then sets the surname to the text to the left of the comma
Then copy these formulas all the way down for every row. And what you see for the results looks like this:
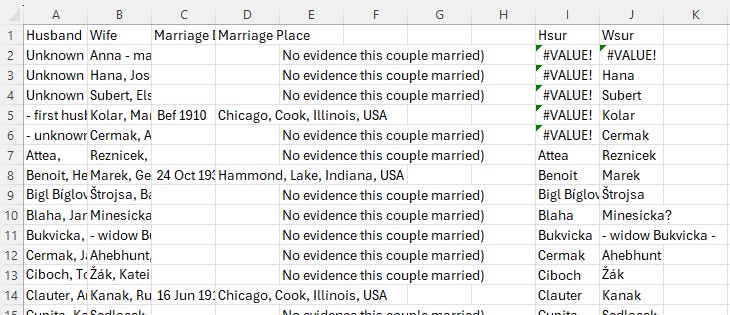
The Input File - Step 3: Remove marriages for which one or both surnames are unknown.
Copy the worksheet to a new worksheet to the left of the original worksheet. Then in the new worksheet, copy the two calculated columns and paste them back on top of themselves using "Paste Special" and checking the circle for "Values". This locks in the surnames so that they are not dependent on the formulas. This allows you to then delete all the columns to the left of the two surname columns so that your worksheet looks like this:
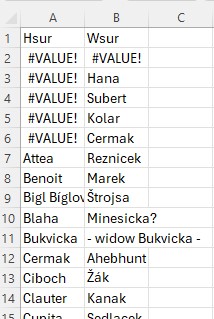
Now go row by row through this worksheet, and delete any row where one or both the husband and wife do not have a surname. For example, in the above image, delete all rows that have "#VALUE!", and delete the row where the wife surname is "- widow Bukvicka -". (If you have a lot of marriages, you can sort by the surnames in order to group the changes to make them easier to deal with.) And now your worksheet looks like this:
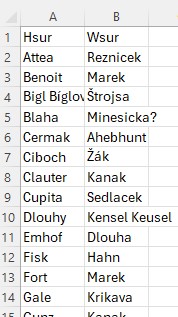
The Input File - Step 4: Standardize the surnames, including removing diacritical marks.
The spelling determines the nodes in the graph. In order for the same family to be considered the correct number of times, their surname has to be the same spelling in every marriage. Some examples: (a) standardize Hahn, Hana and Hann to just one of these spellings (b) Dlouhy and female Dlouha standardize to Dlouhy (a Slavic language convention).
I also remove the diacritical marks and any other punctuation as part of this process. The result is the final list of all the standardized surnames for every marriage that has surnames for both the husband and wife.
The Input File - Step 5: Duplicate the list with the names of the husband and wife switched so that both lists have all the surnames.
The columns we have been calling husband and wife will not be separately included as surname nodes. So, if there are three marriages with wives named Tesinsky, GEPHI will not include the surname Tesinsky if there is no husband with that name. And even if there is a male with the surname, GEPHI will not count the instances of wives in determining how many marriages have the surname Tesinsky as either husband or wife. To remedy this, we copy all the husband surnames and paste them at the end of the wives' surnames list and vice versa.
The Input File - Step 6: Save the file with the first worksheet the one with just the doubled list of surnames.
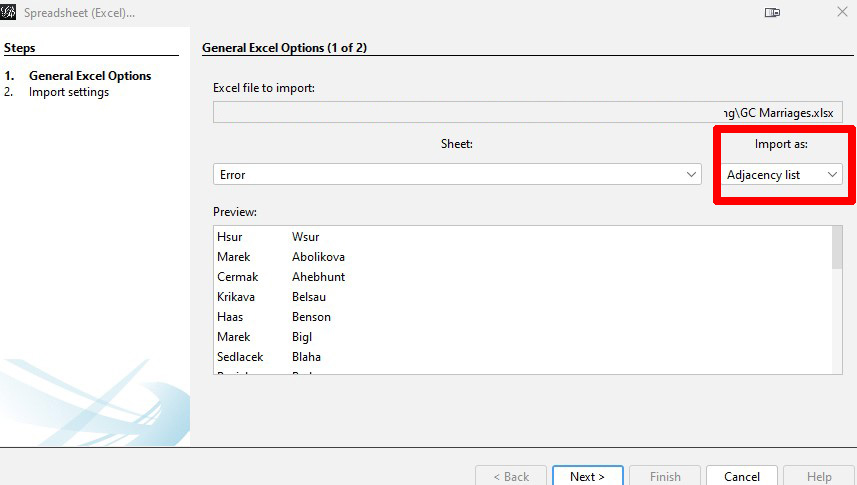
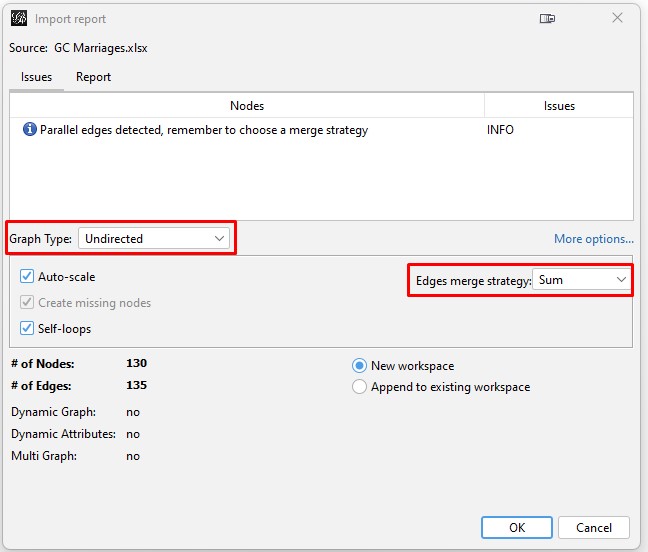
Save the file as an Excel file and not a CSV file. In step 3 above, we copied the surname-only worksheet to be the first (left-most) worksheet in the spreadsheet. Make sure that is where it is when doing the save since GEPHI will look at the first worksheet for the data. You are now ready to begin working with GEPHI.
|